Hi there, I'm Samuel!

I have 5 years of experience in data science, analytics, machine learning, and data engineering across diverse environments — from startups in the consumer goods sector to big tech at TikTok. I also hold a Master's in Computer Science from Georgia Tech.
Samuel’s Portfolio
- Batch ETL pipeline for new releases on Spotify
- Sentiment Analysis of tweets with Deep Learning
- Analysing and Modelling HDB resale prices
- Outlier Detection in Product Matching
- Predicting customer churn
Batch ETL Pipeline for new releases on Spotify
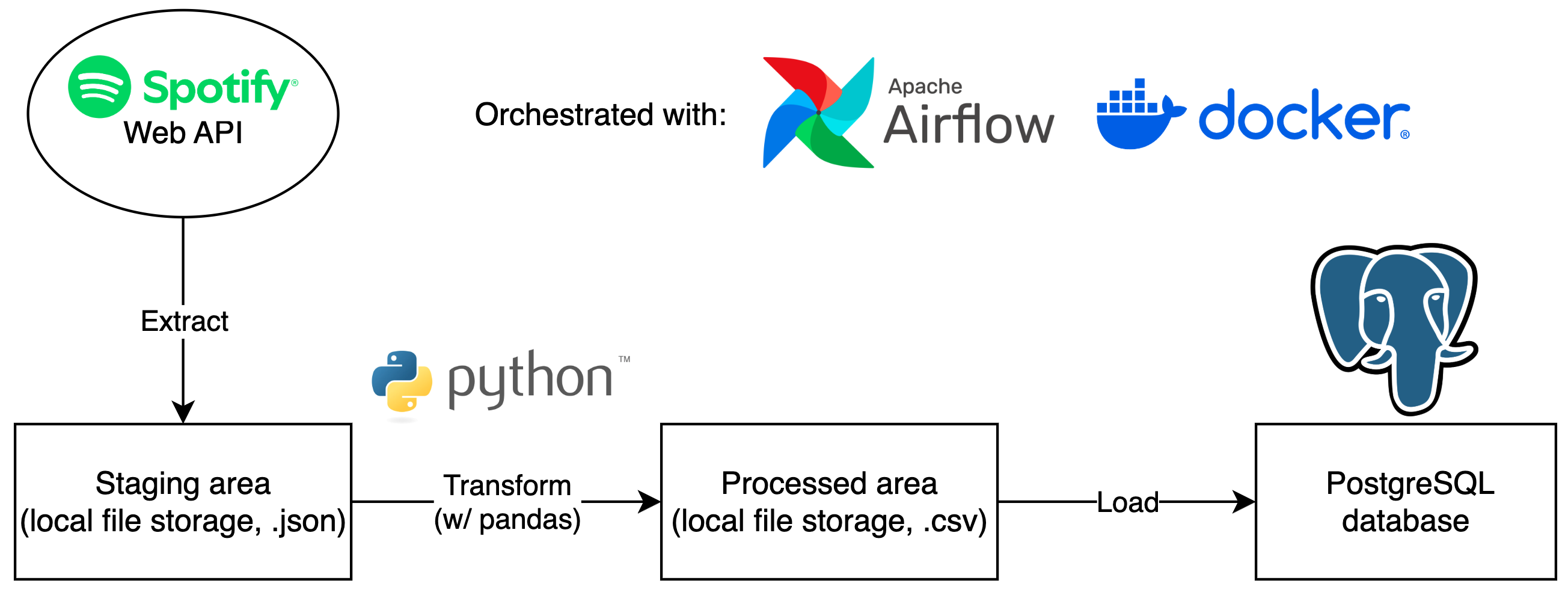
This project involves extracting new Spotify releases via Spotify’s Web API, transforming, and then loading them into a PostgreSQL database. The entire pipeline was orchestrated by Airflow on Docker to run on a daily schedule.
Check out the repo here: https://github.com/samuel-lwl/spotify_etl_public.
Sentiment Analysis of tweets with Deep Learning 🤖

In this project, I explored the Huggingface framework and fine-tuned a pre-trained distilBERT model to outperform the default Huggingface sentiment classification model on the task of sentiment analysis of tweets. The dataset used was the Sentiment140 dataset. I also trained a bi-LSTM model in TensorFlow for comparison.
Lastly, I scraped twitter for recent tweets related to Elon Musk and used the fine-tuned transformer to predict their sentiments.
Analysing and Modelling HDB resale prices

In this project, I explored and visualised public housing resale prices using Plotly from 2017 to 2021 to learn about recent market trends - specifically, the impact of COVID on the market. I also analysed possible factors affecting resale prices.
Supervised learning models were then trained on past data using Scikit-learn and PyTorch and tested on newer unseen transactions, achieving results less than 10% away from the true values on average. Lastly, unsupervised learning models were used to identify interesting patterns in the data by clustering transactions to form house segments.
Outlier Detection in Product Matching

In this short project, I attempted to detect outliers in product names using a combination of word processing techniques and a couple of unsupervised learning models with varying success.
Predicting customer churn

This project involves predicting whether or not a customer is likely to leave a company. Several supervised learning models were trained and compared on their results, with the best model obtaining 80% accuracy.